
Email syntax validation is that first, critical check to see if an email address looks right. It’s all about confirming it follows the classic `local-part@domain` structure. This is your ground floor, the essential first step in data quality that makes sure an address could be real before you waste time and resources on any deeper verification.
Think of it as the bouncer at a club. They're not checking if the ID belongs to the person, just that it's a valid ID card and not a library card. This quick, automated proofread catches the obvious fakes and typos right at the door.
This simple check is your first line of defense against bad data seeping into your lists. It's a foundational step that has a direct ripple effect on your marketing campaigns, sales outreach, and overall business health. By catching simple formatting mistakes as they happen—like a missing "@" symbol, illegal characters, or stray spaces— you instantly stop junk data from ever making it onto your list.
What Is Email Syntax Validation and Why It Matters
At its heart, email syntax validation is about a set of rules. These aren't just made up; they're based on official internet standards that define a structurally sound email address. The history goes all the way back to 1971 when Ray Tomlinson first sent an email using the "@" symbol. Today, standards like RFC 5322 get into the nitty-gritty, specifying that the part before the "@" can't be longer than 64 characters and the domain part can't exceed 255 characters.
This process is about breaking an email down into its basic parts and checking each one against these established guidelines.
Key Takeaway: Syntax validation is a structural check, not a deliverability check. It confirms an email is put together correctly, but it doesn't prove the mailbox actually exists or is active. It's the first, non-negotiable step in a complete verification process.
So, what exactly does a syntax validator look for? Let's break down the basic components.
The Anatomy of a Valid Email Address
The table below outlines the core components that are examined during a syntax check. Each piece must meet specific criteria for the entire address to pass this initial inspection.
Component | Description | Example |
|---|---|---|
The '@' Symbol | The validator confirms there's exactly one "@" symbol, which acts as the separator between the user's name and the domain. | `jane.doe@example.com` |
The Local Part | This is everything before the "@". It's checked for allowed characters, like letters, numbers, and certain special symbols (`.`, `-`, `_`). | `jane.doe@example.com` |
The Domain Part | This is everything after the "@". It must be a valid domain name format, containing letters, numbers, and hyphens, plus a recognized top-level domain (TLD). | `jane.doe@example.com` |
Structural Rules | The check looks for common formatting errors, like addresses starting or ending with a dot, or having two dots in a row. | `[email protected]` (Invalid) |
Essentially, the validator runs through a checklist:
- Is there one—and only one—"@" symbol? An address like `janesmith.com` or `jane@[email protected]` would instantly fail.
- Are the characters in the local part valid? The part before the "@" is checked for things that don't belong, like spaces or certain punctuation.
- Does the domain part look legitimate? The part after the "@" is checked to ensure it looks like a real domain name and ends with a proper top-level domain (TLD) like `.com`, `.org`, or `.io`.
- Are there any misplaced dots? An email can't start or end with a period, and you can't have them back-to-back, like in `[email protected]`.
Getting this first step right is fundamental. It's the difference between building your marketing on a solid foundation versus a house of cards.
Of course. Here is the rewritten section, crafted to sound human-written, natural, and expert-led, while following all your specific instructions.
*
How Email Standards Have Evolved Over Time

The rules for email validation didn't just appear out of nowhere. They were hammered out over decades, shaped by new tech, changing user habits, and landmark government rules that completely changed what it means to communicate responsibly online. This journey explains why modern validation is so much more than just a simple technical check.
In the early days, email felt a bit like the Wild West—mostly unregulated, with very few standardized practices. But as email became a core channel for business and marketing, the need for some law and order was obvious. The game really started to change with the first major anti-spam laws.
The Rise of Regulation and Compliance
The real turning point came when new laws were passed to protect people from deceptive and unwanted messages. These regulations forced businesses to shift their focus from just sending emails to making sure they were sent to real, consenting people.
The U.S. CAN-SPAM Act of 2003 and the EU’s GDPR in 2018 were game-changers. CAN-SPAM was about cracking down on shady practices, but GDPR’s strict requirement for explicit user consent made rigorous email syntax validation a legal and operational must-have. This legislative push, combined with the explosive growth of platforms like Gmail—now serving over 1.8 billion users—forced the entire industry to get a lot smarter. If you're curious, you can dig into the complete history of email and its regulations to see the full picture.
The Impact of Modern Standards: These days, failing to validate your emails isn't just a tech blunder; it's a direct hit to your sender reputation and can land you in legal hot water. Clean, compliant lists are now the absolute foundation of successful email outreach.
The Influence of Major Email Providers
As inbox providers like Gmail, Outlook, and Yahoo ballooned in size, they became the ultimate gatekeepers. Their goal has always been simple: protect their users from spam and deliver a clean, relevant inbox. To pull this off, they built incredibly sophisticated filtering algorithms that scrutinize every single incoming message.
These filters look at way more than just your email's content. They analyze your sending behavior, how people engage with your messages, and—critically—the quality of your email list. Firing off emails to a long list of invalid or non-existent addresses is a massive red flag for them.
This created a whole new set of stakes for anyone sending email:
- Sender Reputation: Your sending domain and IP address are constantly being scored. High bounce rates from a dirty list will drag that score right down into the mud.
- Inbox Placement: A poor reputation means your emails are far more likely to end up in the spam folder, or worse, get blocked before they even have a chance.
- Deliverability: It’s a direct correlation. Clean lists lead to higher deliverability rates, which means your messages actually get to the people you’re trying to reach.
This whole evolution turned email syntax validation from a "nice-to-have" technical chore into an absolutely critical business practice for anyone who wants to survive and succeed in the inbox.
Demystifying The Core Rules Of Email Syntax
To really get a handle on email syntax validation, you have to look past the simple `[email protected]` format we see every day. Think of an email address like a shipping address: it has two distinct parts that work together to make sure it's properly structured for delivery. The official rulebook for this, known as RFC 5322, lays out some surprisingly flexible guidelines for what makes an address structurally sound.
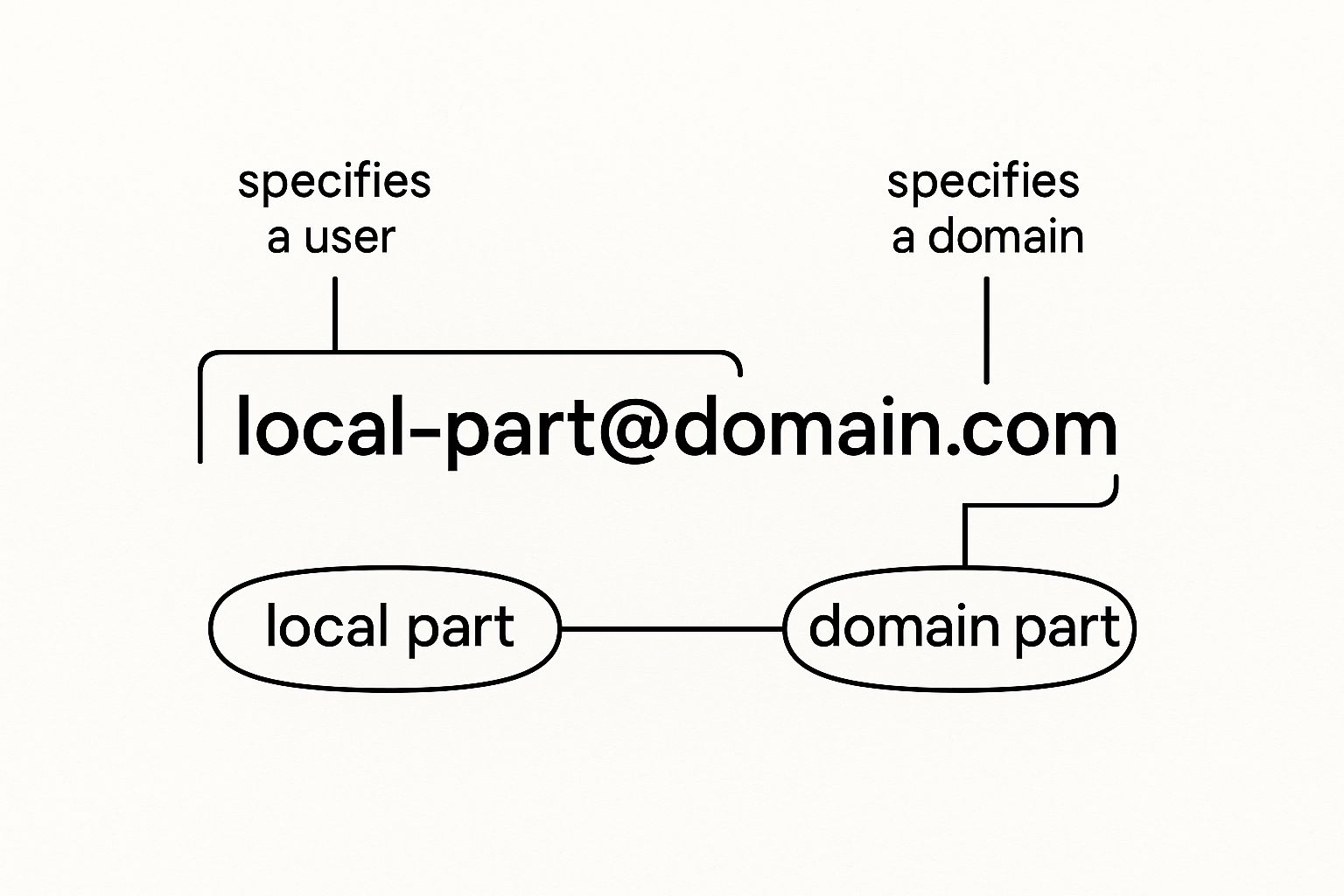
At its heart, every email address is just two key pieces separated by the `@` symbol: the local-part and the domain-part.
This infographic breaks down that fundamental structure, showing how the two parts combine to form a complete, deliverable address.
{kind=link}
Understanding this split is the first real step in appreciating why syntax validation can get so tricky.
Breaking Down The Local-Part
The local-part is everything that comes before the `@` symbol. While it usually looks simple, the official rules allow for a lot of complexity. It can be up to 64 characters long and is typically made up of letters, numbers, and a few special characters like periods (`.`), hyphens (`-`), and underscores (`_`).
But this is where many basic validation scripts get it wrong. The local-part has special rules that permit more than you might expect.
- Sub-addressing: Using a plus sign (`+`) is perfectly valid. For example, `[email protected]` is a legitimate address. Many services incorrectly flag this format, turning away valid users.
- Quoted Strings: The rules also allow for a "quoted string" as the local-part, where almost any character can be used as long as it’s wrapped in double quotes. This means an address like `"a very.unusual email"@example.com` is technically valid, even if you’ve never seen one in the wild.
A common mistake is to assume all email addresses follow a simple, clean pattern. The reality is that official standards are far more permissive, and a rigid validator will inevitably block legitimate emails. This creates a poor user experience and can cost you customers.
Understanding The Domain-Part
The domain-part, which comes after the `@`, is a bit more straightforward but still has its own set of rules. It tells mail servers where to send the email and can be up to 255 characters long.
Its structure has to follow the standards for all domain names:
- Domain Labels: It's made of one or more "labels" separated by dots. In `mail.example.com`, `mail`, `example`, and `com` are all labels.
- Allowed Characters: Labels can only contain letters, numbers, and hyphens.
- Hyphen Rules: A label can’t start or end with a hyphen. This makes `my-domain.com` valid, but `-mydomain.com` is not.
To give you a clearer picture, here’s a quick rundown of some common checks and what they're actually looking for.
Common Email Syntax Checks and What They Mean
Syntax Check | Purpose | Example of Failure |
|---|---|---|
Presence of '@' Symbol | The most basic check. Confirms the address has a local-part and a domain-part. | `jane.doe.example.com` |
No Double Dots | Ensures there are no consecutive periods in the local or domain-part. | |
Valid Local-Part Characters | Checks for allowed characters (letters, numbers, `._-+`) outside of a quoted string. | |
Valid Domain Characters | Verifies the domain only contains letters, numbers, and hyphens. | `jane.doe@example_domain.com` |
Domain Hyphen Placement | Confirms hyphens in the domain are not at the beginning or end of a label. | |
Top-Level Domain (TLD) Check | Ensures the domain ends with a valid TLD like `.com`, `.org`, or `.co.uk`. |
These checks help catch the most obvious typos and malformed entries, but they still only scratch the surface of proper validation.
These detailed rules for both the local and domain parts are precisely why a simple regular expression (regex) often falls short. A regex that’s strict enough to block junk like `[email protected]` might also mistakenly reject a valid address like `[email protected]`.
True email syntax validation requires parsing these rules correctly. This is where a dedicated service like VerifyRight shines, accurately interpreting the full spectrum of valid formats. It ensures you filter out only genuinely malformed addresses without alienating users who have unconventional—but perfectly valid—emails.
Avoiding Common Email Validation Mistakes
When it comes to email validation, a lot of businesses stumble over the same hurdles. They end up with bad data, annoyed users, and money down the drain. An email validation strategy that’s poorly put together can be just as bad as having no strategy at all.
Let's walk through some of the classic mistakes so you can build a process that's both accurate and welcoming to every real customer.
The single biggest culprit? Relying on a shoddy or overly simple regular expression, or regex. A regex is just a pattern-matching tool, but the official rules for what makes an email valid are so complex that one simple pattern can't possibly catch everything. This almost always goes wrong in one of two ways.
First, an overly strict regex will flat-out reject perfectly good emails. For instance, it might not know what to do with sub-addressing, where a `+` symbol is used (like `[email protected]`). Someone trying to sign up with that address gets blocked, creating a frustrating experience and potentially costing you a customer.
Failing to Account for Modern Standards
Another common pitfall is using validation logic that’s stuck in the past. The internet isn't just `.com` and `.org` anymore. We now have hundreds of new top-level domains (TLDs), from `.photography` to `.marketing`.
An old validation script might see an address like `[email protected]` and incorrectly flag it as invalid simply because it doesn't recognize the TLD. You've just alienated a user who has embraced modern domain names.
The same goes for failing to handle international characters—a massive oversight in today's global market.
- Internationalization (SMTPUTF8): Modern email systems can handle non-Latin characters, meaning addresses like `josé@example.com` or `info@例子.com` are completely valid.
- Global Reach: If your forms reject these addresses, you’re effectively shutting the door on a huge portion of your potential audience. Proper email syntax validation absolutely must recognize these international formats to be considered effective.
Key Insight: The goal of validation isn't to force everyone into a narrow, outdated format. It's to correctly identify the full spectrum of legitimate email addresses people actually use today. You don't want to turn away real customers because of a technical blind spot.
The Problem with a "Lazy" Regex
On the other flip side, a "lazy" or overly permissive regex lets all sorts of junk slip through. A pattern that only looks for an `@` symbol and a dot might accept nonsense like `[email protected]` or even structurally broken addresses with double dots, like `[email protected]`.
This kind of garbage pollutes your email list, tanks your sender reputation, and wastes marketing dollars on emails that will never be delivered. This is precisely why a multi-layered approach is so critical. To see what that full process looks like, you can check out our complete guide on how to check if an email is valid.
Ultimately, getting this right means moving beyond basic, error-prone scripts. Once you understand just how complex email standards are, you can adopt a robust validation tool that ensures your data is clean, your users feel supported, and your outreach is built on a rock-solid foundation of accuracy.
Putting Syntax Validation Into Practice
Theory is great, but seeing email syntax validation work in the real world is where it all clicks. It's one thing to talk about rules and standards, but it's another to see how a professional tool handles the email addresses that trip up basic scripts. This is where you see the massive difference between just guessing and actually ensuring good data hygiene.
A dedicated service does way more than just look for an "@" symbol. It carefully applies RFC standards to make sense of all sorts of email formats. This is crucial because it stops you from accidentally turning away real customers who use more complex—but totally valid—email addresses.
From Simple to Complex Cases
Let's look at a few common scenarios where a homemade validation script often falls flat, but a professional tool gets it right every time:
- Standard Email: `[email protected]` - This is the easy one. Pretty much any validator can handle this.
- Sub-Addressing: `[email protected]` - This is where things get interesting. Many simple scripts will choke on the `+` symbol, flagging it as an error. But a proper validator knows this is a legitimate way for users to filter their inboxes.
- International Characters: `josé@example.com` - In a global market, rejecting non-ASCII characters is a huge mistake. A solid service breezes through these internationalized addresses without any issues.
This screenshot from a tool like VerifyRight shows you just how clear and simple the results ought to be.
There's no need to decipher complicated code. The interface gives you an instant, clear verdict on which emails have valid syntax and which don't. That kind of immediate feedback is absolutely essential for keeping your data clean in real-time.
At its core, a specialized tool gives you one thing: confidence. You get a definitive "valid_syntax" or "invalid_syntax" status, which gets rid of all the guesswork and risk that comes with homegrown solutions. You can maintain a pristine email list without having to become a regex guru yourself.
The Impact on Data Quality
At the end of the day, solid email syntax validation is a cornerstone of great CRM data hygiene. It ensures the customer insights you rely on are built from accurate, usable data. Every single invalid email you catch at the point of entry—whether it's on a signup form or during a data import—is one less bounce you have to deal with later.
This proactive approach pays dividends. It doesn't just protect your sender reputation; it makes your entire outreach more effective. You're left with a higher-quality list, which naturally leads to better engagement and a much stronger ROI on your marketing efforts. If you're looking to tackle your data quality head-on, our guide on how to clean an email list is a great place to start.
Using a dedicated service like VerifyRight lets you trust your data and get back to what you do best: connecting with real, interested customers. It’s simply the smart, scalable way to handle the most fundamental layer of email verification.
Looking Beyond Syntax to Full Email Verification
Think of email syntax validation as the first, quick checkpoint at a major event. The security guard glances at your ticket—does it look real? Is it for the right day? It's a basic but essential first step. If the ticket is obviously fake, you're not getting any further.
But just because the ticket looks right doesn't mean you're in.
In the same way, proper email syntax is just the start of the verification journey. It confirms an address follows the standard `[email protected]` format, but it tells you nothing about whether that mailbox actually exists or can receive your email. It’s a crucial first filter, but it’s far from the whole story.
The Next Layers of Verification
To get a complete picture, you have to go deeper. Once you've confirmed the syntax is sound, a full email verification process digs into what really matters: deliverability. It's like moving past the front gate to have your ticket scanned and your name checked against the official guest list.
These additional layers include:
- Domain & MX Record Check: First, the system checks if the domain (`example.com`) is even real and has a mail exchanger (MX) record. This simply confirms a mail server is set up to accept emails for that domain. It's like making sure the venue for the event actually exists before you drive there.
- SMTP Handshake: This is the final, most direct check. The verification service has a quick "conversation" with the receiving mail server. It politely asks if the specific mailbox (`[email protected]`) is active without actually sending an email. This is the moment the scanner beeps green, confirming your ticket is valid and you're on the list.
These deeper checks are what separate a properly formatted address from a genuinely deliverable one. While syntax validation is the starting point, full verification is what protects your sender reputation and makes sure your campaigns actually land.
This multi-step approach ensures you’re not just sending messages to addresses that look right, but to inboxes that are real and ready to receive them. For a detailed breakdown of these steps, you can explore what true email verification entails and how it builds on a solid syntactic foundation.
While syntax validation confirms the format, full email verification often includes deeper checks like domain and sender authenticity. You can learn more about understanding email authentication to enhance your security. This positions syntax validation as the essential start of a robust data quality strategy.
Of course, here is the rewritten section, designed to sound completely human-written and match the provided examples.
*
A Few Common Questions About Email Syntax
Once you start digging into email validation, a few questions always pop up. It's usually the edge cases that trip people up and challenge what seems like a simple task. Let's clear up some of the most common ones.
Is an Email with a Plus Sign Valid?
Yes, absolutely. An email address like `[email protected]` that contains a plus symbol (`+`) is perfectly valid according to official internet standards. This is a feature called sub-addressing, and it lets users create unique aliases for a single inbox to easily filter incoming mail.
Unfortunately, a lot of outdated or poorly configured validation scripts will incorrectly flag these as invalid. Being able to recognize these formats is one of the first signs of a truly robust validation system.
Can I Just Use a Regex for Validation?
While it might be tempting to use a simple regex pattern to catch basic typos, relying on it alone for email syntax validation is a risky shortcut. The official standards (like RFC 5322) that define what makes an email valid are so mind-bogglingly complex that a regex capable of covering every rule would be incredibly slow and a nightmare to maintain.
More often than not, simple regex patterns fall into one of two traps: they're either too strict (and end up rejecting valid addresses with plus signs or new top-level domains) or far too lenient (letting junk like `[email protected]` slip through). A dedicated validation service is always the more reliable and accurate approach.
Does Syntax Validation Guarantee Deliverability?
No, and this is a critical distinction to understand. Think of syntax validation as just the first step. It simply confirms that an address is formatted correctly—like checking if a physical mailing address has a street name and a zip code.
It doesn't, however, tell you if the domain actually exists, if its mail server is online, or if that specific mailbox is active and can receive email. To confirm that an email will actually be delivered, you need to perform a full email verification, which involves deeper checks like MX record lookups and SMTP handshakes.
---
Ready to move beyond basic checks and get your email lists truly clean? With VerifyRight, you can implement real-time, accurate syntax validation and full verification to protect your sender reputation and boost your deliverability. Try our free API and start cleaning your lists today.