
When it comes to email validation in Python, you're essentially using scripts and specialized libraries to figure out two things: is an email address formatted correctly, and can it actually receive mail? This can be as simple as a syntax check with regex or as complex as performing SMTP handshakes and API calls to confirm a mailbox genuinely exists. Getting this right is crucial for keeping your data clean.
Why Basic Python Email Validation Fails

As a developer, your first instinct might be to grab a quick and dirty solution. Most of us have done it—cobbling together a simple regular expression that just looks for an "@" symbol and a period. It feels efficient, but this is a classic trap that leads to collecting bad data. Superficial validation only creates a false sense of security while letting all sorts of invalid emails slip right into your database.
The real-world consequences of this are bigger than you might think. Bad email addresses directly cause high bounce rates, which can absolutely tank your domain's sender reputation. Before you know it, internet service providers start noticing and might flag your legitimate emails as spam, torpedoing your deliverability across the board.
The Problem with Single-Layer Checks
One of the most common methods for Python email validation is using regular expressions (regex) to check an email's syntax. It’s a fast way to see if an address fits the basic structural rules, like having an '@' symbol and a domain. While regex is quick, its major flaw is that it only verifies the format. It has no idea if the email actually exists or can receive messages.
This is where so many applications fall short. A truly reliable validation system needs to check things in layers:
- Syntax Validation: Is the format correct (e.g., `[email protected]`)?
- Domain Validation: Does the domain (`domain.com`) actually exist and have mail servers?
- Mailbox Validation: Does the specific user (`user`) have a mailbox at that domain?
Relying on just one of these—especially syntax alone—is a common but costly mistake.
Key Takeaway: Just because the format is valid doesn't mean the email is. An address like `[email protected]` can easily pass a basic regex check but will bounce the second you try to send to it, wasting your resources and damaging your sender score.
It's also important to connect the dots between invalid emails and business metrics. For example, poor email quality is a major reason why you might see leads going cold—your critical follow-ups simply never arrive. This guide will walk you through building a validation process that actually protects your data quality and moves far beyond a simple regex check.
Crafting a Smarter Regex for Syntax Checks
Let's be real: just checking for an "@" symbol is a rookie mistake. But a well-crafted regular expression (regex) is still the perfect first line of defense for any serious python email validation process. Think of it as a quick, efficient bouncer at the door, turning away obviously fake addresses before you waste time and resources on more intense checks.
It’s time to move beyond those generic, copy-pasted patterns you find online and build a regex that actually gets the job done.
A smarter regex isn't just about spotting an "@". It's about enforcing the basic rules of email structure. It confirms the local part (before the @) and the domain part (after the @) follow standard conventions. This simple step prevents common junk like addresses with spaces or multiple "@" symbols from ever getting through your system.
Dissecting a Robust Regex Pattern
Have a look at this more robust pattern. It’s a huge step up from the simplest checks and gives you a solid foundation for syntax validation.
import re
def is_valid_syntax(email):
# A more comprehensive regex for email syntax validation
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if re.match(pattern, email):
return True
return False
--- Examples ---
print(is_valid_syntax("[email protected]")) # Outputs: True
print(is_valid_syntax("[email protected]")) # Outputs: True
print(is_valid_syntax("[email protected]")) # Outputs: True
print(is_valid_syntax("no [email protected]")) # Outputs: False
print(is_valid_syntax("missing-at-sign.com")) # Outputs: False
So, what’s actually happening under the hood here? Let's break it down:
- `^`: This asserts that the pattern must start at the beginning of the string. No leading characters allowed.
- `[a-zA-Z0-9._%+-]+`: This matches the "local part"—one or more alphanumeric characters, plus common special characters like periods, underscores, and plus signs.
- `@`: It looks for the literal "@" symbol. Simple enough.
- `[a-zA-Z0-9.-]+`: This part matches the domain name—one or more alphanumeric characters, periods, or hyphens.
- `\.`: Here, we escape the period to match a literal dot, separating the domain from the TLD.
- `[a-zA-Z]{2,}`: This bit handles the top-level domain (TLD), ensuring it has at least two letters (like `.io` or `.com`).
- `$`: Finally, this asserts the pattern must end at the very end of the string.
This pattern is way more effective because it validates the characters allowed in each part of the address and makes sure the TLD has a reasonable length. It’s a workhorse.
Handling Common Pitfalls and Edge Cases
Even a good regex has its blind spots. The biggest trap I see people fall into is using an overly strict pattern. This creates false negatives, rejecting perfectly valid emails and frustrating legitimate users who are trying to sign up.
For instance, a pattern like `\.[a-zA-Z]{2,4}` was common years ago, but it's completely outdated now. With the explosion of new generic top-level domains (gTLDs) like .photography or .technology, that old rule would incorrectly block them. Our example, `\.[a-zA-Z]{2,}`, is much more future-proof.
Another huge pitfall is internationalization. Email addresses can contain non-ASCII characters (e.g., `josé@example.com` or `東京@domain.jp`), and the standard regex above would choke on them. Honestly, trying to build an impossibly complex regex to handle every language is a fool's errand. For apps supporting international users, your best bet is to use a dedicated library that understands these nuances.
Ultimately, a smart regex is a balancing act. You need it to be strict enough to block obvious junk but flexible enough to accept the huge variety of valid email formats out there today. It's an absolutely essential first step, but it's definitely not the final word in your validation workflow.
Confirming Deliverability with SMTP Handshakes

Alright, so you've used a regex to filter out the obvious typos and syntactically wonky addresses. What's next? The real test is finding out if the mailbox actually exists. This takes our python email validation from a simple format check to a genuine deliverability test.
The trick is to do this without actually sending an email. We can accomplish this by performing what’s known as a Simple Mail Transfer Protocol (SMTP) handshake.
Think of it as politely knocking on the recipient's mail server door and asking, "Does Jane Doe live here?" The server's response tells you if the address is deliverable. This involves two key steps: first, finding the domain's Mail Exchange (MX) records, and second, starting a conversation with that server.
The Two-Step SMTP Verification Process
Before you can even talk to a mail server, you need to know where it is. That's the first step. You query the Domain Name System (DNS) for the domain's MX records, which are basically signposts pointing to the servers that handle its email.
Once you have the server's address, you can kick off the SMTP conversation. Your script connects to the server and runs through a sequence of commands, mimicking the first few moments of an actual email delivery.
Here's a rough sketch of how that conversation goes:
- HELO/EHLO: Your script introduces itself to the server.
- MAIL FROM: You provide a sender's address (it can be a dummy one).
- RCPT TO: This is the moment of truth. You ask about the specific email address you're validating.
The server's reply to that `RCPT TO` command is what we're after. A friendly response code, like 250, suggests the address is good to go. An error, like 550, is a strong signal that it doesn't exist.
The Significant Risks and Challenges
While this method sounds powerful, it's not a silver bullet and comes with some serious risks. Many modern mail servers are wise to these kinds of checks and are set up to fight spam, which means they might give you misleading answers.
For example, some servers have a "catch-all" configuration. This means they'll accept mail for any address at that domain, making it impossible to verify if an individual mailbox truly exists.
The single biggest risk of running SMTP checks from your own server is getting your IP address blacklisted. If a mail server sees too many connection attempts or validation checks from a single IP, it may flag you as a potential spammer. This can have devastating consequences, blocking all outgoing mail from your application, not just the validation attempts.
A robust python email validation strategy combines multiple layers. It starts with regex but adds DNS and SMTP checks to confirm a domain is valid and a mailbox actually exists. To pull this off, you'll need Python modules like `dnspython` for the MX lookup and `smtplib` for the handshake itself. It’s more work, but it dramatically improves your accuracy.
In the end, a failed SMTP check is a very strong sign that an email is bad. A successful check, however, isn't a 100% guarantee because of things like catch-all servers.
For a deeper look at keeping your emails out of the spam folder, check out these proven strategies to improve email deliverability. You can also learn more about how to improve email deliverability with our own comprehensive guide.
Using Third-Party APIs for Reliable Validation
While SMTP handshakes offer a much deeper check than regex, they open up a whole new can of worms. Trying to perform these checks at scale from your own server is a risky game. This is where third-party APIs come in, offering a far more robust, scalable, and safer path for serious python email validation.
Handing this job off to a specialized service might feel like giving up control, but it's really about gaining reliability. If you manage your own SMTP validation, you're constantly on edge about your server's IP reputation. Mail servers are notoriously sensitive to repeated connection attempts from a single IP address—a dead giveaway when you're validating a large list.
This is a fast track to getting your IP blacklisted, which is a total disaster. Suddenly, all your application's legitimate outgoing mail, from password resets to critical notifications, could get blocked. A third-party API provider takes on this burden, distributing checks across a huge network of servers to keep your reputation clean.
The Practical Advantages of an API Approach
The benefits go way beyond just staying off blacklists. Professional validation services have poured years into refining their algorithms. They’ve learned to interpret the thousands of cryptic, non-standard responses that mail servers spit back. What your script sees as a simple "invalid" might have nuances a dedicated service has learned to understand.
This expertise is absolutely vital for tricky situations like:
- Catch-All Servers: These domains are configured to accept any email sent to them, making it impossible to confirm a specific mailbox exists via SMTP. A good API can often identify these domains, letting you flag these addresses for different handling.
- Greylisting: Some servers will temporarily reject mail from unknown senders, expecting a legitimate server to just try again later. Building and managing this retry logic yourself is a complex and resource-draining headache.
- Disposable Email Detection: APIs maintain constantly updated databases of temporary email providers (think Mailinator), helping you block low-quality sign-ups at the source.
Key Insight: Building a basic validation script is easy. Building a reliable one that can navigate the messy, unpredictable reality of the global email system is exceptionally hard. An API lets you tap into a system that has already solved these tough problems.
Calling a Verification API with Python
Plugging a validation API into your Python code is usually pretty simple. Most services, including our own VerifyRight API, offer a clean REST endpoint you can hit with a library like `requests`.
Here’s a quick look at how you might check an email in the real world:
import requests
import json
Your API key and the email to validate
API_KEY = "YOUR_VERIFYRIGHT_API_KEY"
email_to_check = "[email protected]"
The API endpoint
url = f"https://api.verifyright.io/v1/verify?email={email_to_check}"
headers = {
"Authorization": f"Bearer {API_KEY}"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # This will raise an HTTPError for bad responses (4xx or 5xx)
Parse the JSON response
validation_result = response.json()
print(json.dumps(validation_result, indent=2))
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
The response you get back is typically a straightforward JSON object. It gives you a clear status like `'valid'`, `'invalid'`, `'disposable'`, or `'catch-all'`, providing actionable data you can immediately use in your application.
Attempting large-scale email validation with Python scripts often runs headfirst into spam defenses like greylisting and IP blacklisting. These protections are designed to block or slow down exactly the kind of activity a verification script generates, making it an unreliable method for big lists.
To put it in perspective, a dedicated service can validate about 100,000 emails in roughly 45 minutes by expertly navigating these restrictions—a speed that's nearly impossible to achieve with a script running on a single server. You can find a more detailed breakdown of Python email verification challenges and see how API services get around them.
Building a Hybrid Python Validation Workflow
Relying on just one method for python email validation is a recipe for letting bad data slip through. A quick regex check is fast but only scratches the surface. An SMTP check is much more thorough, but it can be risky and slow. From my experience, the sweet spot is combining these techniques into a single, smart workflow that gives you the best of all worlds: speed, accuracy, and safety.
Think of it as creating a multi-layered defense for your sign-up forms. The core idea is to "fail fast." You want to filter out the obvious junk immediately before you spend time or resources on the more intensive checks. This approach creates a snappy user experience while still ensuring your data is rock-solid on the back end. It’s a pragmatic strategy I always recommend for any production-level application.
This flow chart gives you a visual of how this layered approach works in practice, starting with an instant syntax check and then escalating to a more robust domain and deliverability verification.
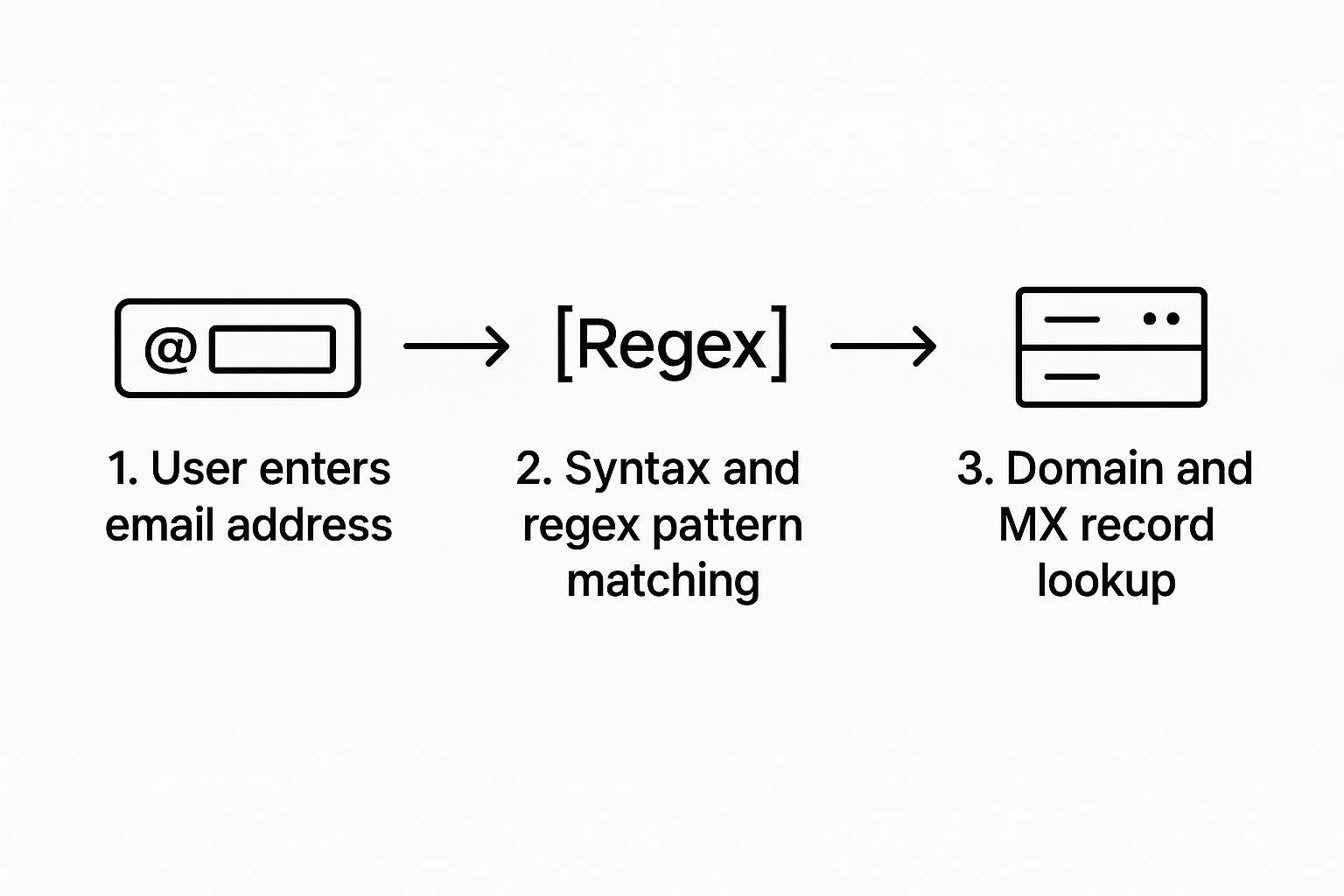
The real power here is that each stage acts as a gatekeeper. Only the email addresses that pass one check get to move on to the next, more resource-intensive step. It’s incredibly efficient.
Orchestrating The Layered Checks
So, how does this actually work?
First, when a user submits an email, your application should immediately hit it with a strong regex pattern check, just like the one we covered earlier. This is your frontline defense. It provides instant feedback, catching simple typos or formatting mistakes right in the browser without any network delay.
If the email makes it past that initial syntax gate, the workflow kicks into its second layer. This is the crucial part: instead of running a risky SMTP check from your own server, you make an asynchronous call to a trusted third-party API like VerifyRight.
Handing off this part of the process is a game-changer. The API takes care of all the messy details—MX lookups, SMTP handshakes, and sniffing out those tricky disposable or catch-all domains.
By making the API call asynchronous (meaning, it runs in the background), you don't freeze the user interface. The user can continue with the sign-up process while the deeper validation happens behind the scenes. You can just mark the email as "unverified" until you get a final thumbs-up or thumbs-down from the API.
This hybrid system gives you a clear and effective blueprint. For a more detailed look at designing these kinds of processes, check out our guide on building an effective email verification workflow.
Here’s a conceptual Python snippet showing how you might structure this flow:
import re
import requests
def run_hybrid_validation(email):
# Layer 1: Instant Regex Check
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if not re.match(pattern, email):
return {"status": "invalid", "reason": "syntax_error"}
Layer 2: Asynchronous API Call (conceptual)
In a real app, this would be a background task (e.g., using Celery, RQ)
print(f"'{email}' passed syntax. Sending to API for deep validation.")
# result = call_verification_api(email) # Placeholder for API call
# return result
return {"status": "pending_api_check"}
Example Usage
print(run_hybrid_validation("[email protected]"))
print(run_hybrid_validation("not-an-email"))
This model is not just accurate; it’s also highly efficient. You only incur the performance cost of an API call for emails that are already syntactically valid, saving you resources and keeping your application running smoothly.
Common Questions About Python Email Validation

As you start building out an email validation system in Python, a few questions almost always pop up. I've seen them come up time and again. Getting clear answers from the get-go can save you from falling into common traps and help you build a much more robust process.
So, let's tackle some of the most frequent queries I hear from developers about python email validation.
One of the first things people ask is about scope: can you just get by with a simple regex? While a regular expression is a great first-pass check for an email's format, that’s pretty much where its usefulness ends.
A regex has no way of knowing if the domain is real or if the specific mailbox actually exists on that server. If you rely on it exclusively, you’re guaranteed to let invalid emails slip through. This leads directly to higher bounce rates, which can seriously damage your sender reputation over time.
Understanding Deeper Validation Concepts
Once you get past basic syntax, you run into trickier scenarios like "catch-all" domains. So, what exactly is a catch-all email address? It's a server that's configured to accept email for any address at that domain, even ones that don't exist.
This setup makes it impossible to confirm a specific mailbox using a standard SMTP check. This is where a professional API really shines. These services can often identify catch-all domains, letting you flag those emails for caution or even manual review. Having a solid grasp of what is email verification and its different layers is crucial here—it goes far beyond a simple pattern match.
Key Insight: Running your own SMTP checks is far riskier than it seems. Mail servers are highly sensitive to numerous verification attempts from a single IP and can easily blacklist you, suspecting spam activity.
This brings us to another critical question: is it safe to perform SMTP checks directly from your application's server? The short answer is no. Honestly, it's a huge risk.
If your server's IP gets blacklisted, it doesn't just block your validation attempts—it can bring all outgoing emails from your application to a grinding halt. We're talking about essential user communications like password resets, purchase receipts, and important notifications.
Using a third-party API service is a much safer and more reliable path. These services manage the risk by distributing their checks across a massive, managed network of IP addresses. This protects your sender reputation while still delivering accurate results. It offloads a significant operational headache, letting you focus on what you do best: building your application's core logic.
---
Ready to build a truly reliable email validation system? VerifyRight offers a developer-focused API that handles the complexity for you. Get 200 free checks every month and see the difference clean data can make. Start validating for free.